
Http高并发服务器项目
1. 简介
该项目的架构是B/S架构,也就是说客户端是浏览器,在本地随便一个浏览器即可;服务器是在linux上搭建的一个应用程序,该程序可以是多线程版的,也可以是单反应堆模型或者是多反应堆模型,反正最终都可以给客户端提供服务。
过程:
客户端(浏览器)向服务器发送一个Http请求,服务器就能把指定目录下的资源给到客户端(浏览器),浏览器就能将得到的数据展示到界面上。如果解析不了该文件,就会自动下载到本地,如果能够展示,它在本地指定的下载目录是不会有对应文件的,因为它下载到本地之后,就直接将内容显示到窗口上了,可以理解为它下载下来的只是一个缓存,该缓存能够支撑它在浏览器上把内容显示出来,当数据显示完成之后,浏览器会定期地清除缓存,那么该资源也就不存在了。
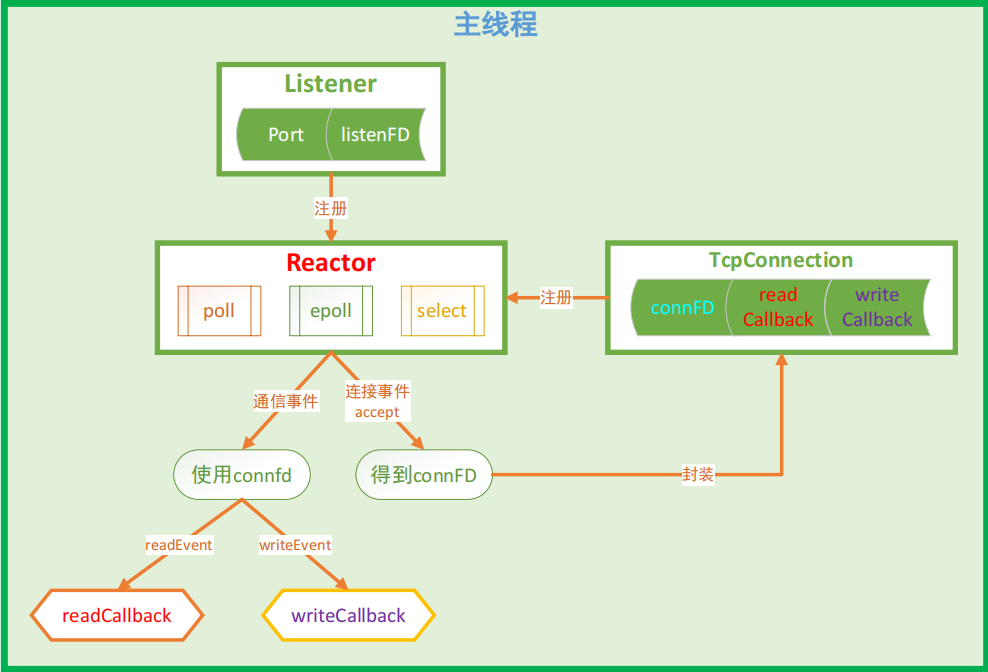
2. 单反应堆的服务器模型
在网络编程中,为了提高访问通信的效率,就可以使用单反应堆的服务器模型,它是IO多路复用与多线程相结合的一种技术。
设计思路:
在主线程里面,服务器绑定本地的ip和端口来得到一个通信的套接字,因为通信的套接字需要监听它的读事件,所以就将它的读事件注册给Reactor,也就是反应堆模型。该反应堆模型底层用到的是poll、epoll或select,这三种IO多路转接技术不是同时用,而是选择其中的某一种。在选择了底层的IO模型之后,把用于监听的文件描述符的读事件注册给该模型,然后内核就可以帮助我们检测这用于监听的文件描述符的读事件是否被激活了。如果被激活了,说明有新连接到达,那么我们就需要调用用于监听的文件描述符对应的处理函数,该处理函数其实就是负责与对端建立新连接,主要的处理核心动作核就是调用accept()函数,因此就能得到一个用于通信的文件描述符,然后对该通信描述符进行一个封装。在封装的时候,给该用于通信的文件描述符指定了读回调和写回调,至于为什么要指定读写回调,是因为反应堆模型就是基于回调的。TcpConnection模型当检测到了对应的文件描述符它的读事件或写事件被触发了之后,该框架就会自动的调用这个事件的处理函数,这种机制就称为反应堆机制。其实本质就是回调函数。
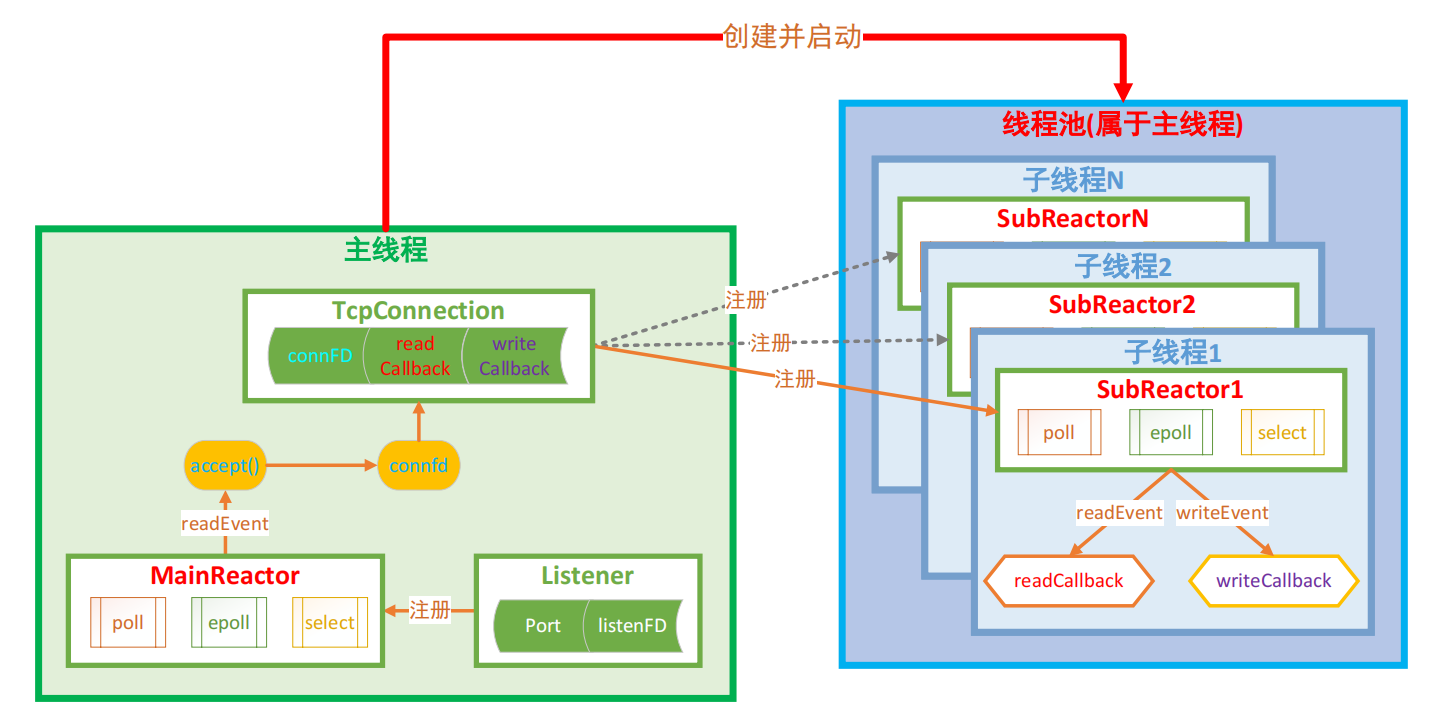
3. 多反应堆的服务器模型
对于多反应堆模型,反应堆的数量取决于线程的数量。
在主线程里面,它是有一个用于监听的套接字Listener,我们需要将它注册给主线程的MainReactor反应堆模型。在主线程的反应堆模型里面可以选择poll、epoll或select,它们就能帮助我们检测对应的监听文件描述符的读事件是否被触发。如果被触发了,就需要建立一个新连接,调用accept()函数得到一个新的用于通信的文件描述符connfd。然后对它进行封装,封装时为它指定一个读回调和写回调。又因为这是一个多反应堆模型,在得到了用于通信的套接字之后,就不要在主线程里面做通信了,把通信交给主线程的线程池,在主线程的线程池里面有多个子线程,每个子线程里面也有一个反应堆模型,该反应堆模型里面主要就是指定的IO多路转接poll、epoll或select。
然后我们只需要把用于通信的文件描述符的事件注册给到对应的子线程的反应堆模型(随机给的),因为这个过程是做了注册的,所以当用于通信的套接字,它的读事件或写事件触发了,对应的回调函数就会知道。当真正的事件被触发之后,子线程里的反应堆模型就会调用响应的处理函数。
4. Http协议
4.1 http请求
属于应用层协议,位于最上层,通过这个协议就可以对通信的数据进行封装。如果网络模型是B/S结构,就必须使用http协议,https协议是在http协议的基础上做了加密。
在数据发送之前,使用协议对数据进行封装,接收到数据之后,按照协议格式解析接收到的数据。
Http协议分为两部分:
1.http请求
客户端给服务器发送数据,叫
http请求,有两种请求方式get请求
post请求
2.http响应
- 服务器给客户端回复数据叫做
http响应
http协议封装好数据之后是一个数据块,得到若干行数据,使用的换行符是\r\n。通过这个\r\r进行判断,就知道这行是否结束了。
http请求消息分为四部分:
1.请求行
- 不管get请求还是post请求,请求行是分为三部分
2.请求头
3.空行
4.客户端向服务器提交的数据
如果使用get方式提交数据,第四部分是空的。
get与post分析比较:
从给服务器发送的数据的量上来分析
- get:主要是向服务器索取数据,提交的数据量比较少
- post:上传文件一般都会使用post,可以提交的数据量是非常大的
从上传的数据安全性来分析
- get:提交的数据不安全,提交的数据会显示到地址栏中,数据容易被泄露
- post:提交的数据并不会显示到地址栏中,完全不可见的,因此更安全
4.2 get请求
下面是浏览器对用户的请求数据进行了封装之后,得到的原始的http请求数据:
1 | GET / |
第1行是请求行:分为3部分,
第1部分是请求的方式,主要有两种,一种是get,另一种是post。如果客户端给服务器发送的是get请求,说明请求的是服务器上的静态文件,即就是在服务器上,这些文件已经被提供好了的(就是在服务器上已经存在的文件),我们通过浏览器向服务器发起一个访问某个文件的请求,这就是get请求。
第2部分是请求的资源,/代表服务器提供的资源目录(不代表是服务器的根目录),该资源目录可以是服务上的任意一个目录,只要存在即可。
第3部分是http的版本,现在一般用的都是http的1.1版本
第2-8行是请求头:由若干个键值对组成:
Host表示要连接的服务器是192.168.88.93,绑定的端口是9393;
Connection的keep-alive表示客户端想要与服务器一直保持连接
User-Agent表示浏览器的版本,指的是内核版本
Accept-Encoding设置压缩的方式使用的是gzip
Accept-Language设置默认的语言
注意:如果我们使用的是get请求,并且get请求里面携带了一些动态数据,这些数据会出现在浏览器的地址栏里面,而该地址栏它的缓存是有上限的,因此如果携带的数据量很多,后面的数据就会丢失。
第9行是空行,空行完之后,就是通过这个请求协议给服务器提交的数据。如果是get请求,这部分内容是空的。因为如果通过get请求向服务器提交动态数据,这个动态数据也不会出现在请求协议的第4部分,而是出现在请求行的第2部分,即:

4.3 post请求
下面是post请求数据的格式
1 | POST / |
如果我们通过post向服务器提交数据,那么这个数据肯定是动态的,即请求的数据在服务器上是不存在的。如注册账号,向服务器提供用户名和密码等信息。
第1行是请求行:分为3部分,
第1部分是请求的方式,主要有两种,一种是get,另一种是post。如果客户端给服务器发送的是get请求,说明请求的是服务器上的静态文件,即就是在服务器上,这些文件已经被提供好了的(就是在服务器上已经存在的文件),我们通过浏览器向服务器发起一个访问某个文件的请求,这就是get请求。
第2部分是请求的资源,/代表服务器提供的资源目录(不代表是服务器的根目录),该资源目录可以是服务上的任意一个目录,只要存在即可。
第3部分是http的版本,现在一般用的都是http的1.1版本
第2-12行是请求头:由若干个键值对组成:
- Content-Length表示提交的内容长度
- Content-Type表示客户端向服务器提交的数据块的格式(还有其它很多种格式)
第13行是空行\r\n
第14行是客户端向服务器提交的数据块
4.4 http响应
服务器给客户端回复数据,称之为http响应,协议的格式分为四部分::
1.状态行2.消息报头/响应头
3.空行
4.回复给客户端的数据块
- http响应消息也是一个数据块,若干行组成,换行是\r\n
响应消息(Response)
1 | Http/1.1 200 Ok |
第1行是状态行,分为3部分:
Http的版本
服务器对客户端请求的处理状态(状态码),200就代表处理成功了
是对状态码的描述
第2到9行是响应头,由一系列的键值对组成:
- Content-Type:表示的是http响应消息,响应的数据块的格式,text/plain代表的是一个纯文本,charset表示使用的字符编码
- Content-Length:表示服务器给客户端回复的数据块的大小(要准确,不确定的话就不写)
第10行是空行
第11到16行是http响应给客户端的信息
http状态码类别:
状态码有三位数字组成,第一个数字定义了响应的类别,共分5种类别:
- 1xx:指示信息–表示请求已经被接收,没有处理完,还正在处理
- 2xx:成功–表示请求已被成功接收、理解、接受
- 3xx:重定向–要完成请求必须进行更进一步的操作(网络地址的重新访问)
- 4xx:客户端错误–请求有语法错误或请求无法实现
- 5xx:服务器端错误–服务器未能实现合法的请求
常见的状态码:
| 状态码 | 状态描述 | 文字描述 |
|---|---|---|
| 200 | OK | 客户端请求成功 |
| 400 | Bad Request | 客户端请求有语法错误,不能被服务器所理解 |
| 401 | Unauthorized | 请求未经授权,这个状态码必须和WWW-Authenticate报头域一起使用 |
| 403 | Forbidden | 服务器收到请求,但是拒绝提供服务 |
| 404 | Not Found | 请求资源不存在,如:输入了错误的URL |
| 500 | Internal Server Error | 服务器发送不可预期的错误 |
| 503 | Server Unavailable | 服务器当前不能处理客户端的请求,一段时间后可能恢复正常 |
整个处理流程:
首先调用threadPoolInit()函数,得到线程池的实例,得到该实例后,调用threadPoolRun()把线程池启动起来,即把线程池里面的子线程启动起来。然后就可以通过takeWorkerEventLoop()从线程池里面取出某一个子线程,得到子线程就能够得到对应的反应堆evLoop实例,将其返回给函数的调用者。调用者就可以通过这个evLoop实例往它的任务队列里面添加任务,当任务添加到evLoop对应的任务队列过后,就可以开始处理这个任务队列了,再根据这个任务队列节点的类型来处理这个dispatcher的检测集合。有3种情况,第1种是往检测集合里面添加新的节点;第2种是往检测集合里面删除节点;第3种情况就是修改检测集合里面某个文件描述符对应的事件。dispatcher这个检测集合处理完毕之后,对应的反应堆模型就开始进行循环了,它需要循环的调用底层的poll、epoll_wait或select来检测这个集合里面有没有激活的文件描述符。如果有激活的文件描述符,那么就通过这个文件描述符找到对应的channel,找到chennel后,然后再基于激活的事件,调用事件对应的回调函数,该回调函数调用完之后,对应的事件也就处理完毕了。
5. 多反应堆+线程池高并发服务器
该项目的结构如下:

在main()函数中,接收外部传来的两个参数,即监听的端口和资源目录,通过传入端口和指定线程池中子线程的个数,得到一个TcpServer服务器实例,并对其进行启动。
1 | int main(int argc, char* argv[]) |
5.1反应堆模型
文件描述符封装类channel
头文件:
1 | //定义函数指针 |
功能实现文件:
1 | //实例化一个channnel |
封装channel的容器类ChannelMap
头文件:
1 | //该结构体主要就是想通过list下标,即fd来找到对应的channel |
功能实现文件:
1 | //实例化channelmap容器 |
IO复用技术类dispatcher
结构体成员都是函数指针
1 | struct EventLoop; //不管该结构体现在是否被定义出来,先告诉编译器有这种类型,下面就可以用这种类型去定义变量(Dispatcher和eventloop互包含了) |
epoll实现:
1 |
|
select实现:
1 |
|
poll实现:
1 |
|
事件循环类EventLoop
1 | extern struct Dispatcher EpollDispatcher; //如果在某个文件中要使用其它文件里定义的全局变量时,需要添加关键字extern |
功能实现文件:
1 | struct EventLoop* eventLoopInit() |
5.2 多线程
线程池类ThreadPool
1 | //定义线程池 |
功能实现文件:
1 | struct ThreadPool* threadPoolInit(struct EventLoop* mainLoop, int count) |
工作线程类WorkerThread
1 | //定义子线程对应的结构体 |
功能实现文件:
1 | int workerThreadInit(struct WorkerThread* thread, int index) //参1是在外部创建好的一块结构体空间,然后传入的是指向该结构体的指针 |
5.3 IO模型
读写缓存区类Buffer
1 | struct Buffer { |
功能实现函数:
1 | //要使用memmem()函数不仅要有头文件<strings.h>,还需要定义宏_GNU_SOURCE |
Tcp通信类TcpConnection
1 | //注释该宏,就是边读边写模式 |
功能实现文件:
1 | //子线程反应堆对应的读回调函数(处理读到的数据,即客户端给服务器发生的数据。将要发送的数据写到writebuf) |
5.4 服务器
TcpServer类
1 | struct Listener { |
功能实现文件:
1 | //对结构体TcpServer进行初始化 |
5.5 Http
接收请求类HttpRequest
1 | //请求头键值对 |
功能实现文件:
1 |
|
组织响应体类HttpResponse
1 | //定义状态码枚举类 |
功能实现文件:
1 | struct HttpResponse* httpResponseInit() |
流程:
从main()函数开始,先通过函数tcpServerInit()创建一个服务器的实例,并设置了主线程启动后,它线程池里面的子线程个数为4,这样就得到了一个服务器的实例对象server,随后就可以调用它的一个Run方法了。
在启动服务器的时候,就是把线程池启动起来,并且把用于监听的套接字用于封装,然后把它放到了当前主线程对应的反应堆模型里面,之后主线程的反应堆模型就运行起来了,那么它底层的pool、epool或select也就运行起来了。它就可以检测监听描述符lfd里面的事件,这里是指读事件。如果有新的客户端连接,读事件就触发了,然后读回调函数acceptConnection就被调用了。
在读回调函数acceptConnection里,它第一件事就是和客户端建立连接得到了一个通信的文件描述符,然后从主线程里面取出了一个子线程,并且把子线程的反应堆模型evLoop取出来,然后把用于通信的文件描述符放到了evLoop里面。在tcpConnectionInit()函数里面,其实就是把cfd进行了封装,最终得到了一个新的channel,然后把这个channel放到了evLoop子线程的反应堆模型里面。
总的来说,就是当主线程建立连接之后,它并不会去处理与客户端的通信,和客户端的通信全都是在子线程里面处理的。
 微信
微信- 支付宝











